
앞선 글에서는 YOLOv8와 Roboflow를 활용해 클라이밍 이미지에서 얼굴, 손, 발을 찾기 위한 데이터셋을 만드는 과정이었다. 이제는 앞서 직접 만든 데이터셋을 활용해 모델 학습과 예측을 하는 과정이다.
1. 데이터셋
여기서는 앞서 Roboflow에서 복사한 코드를 붙여넣으면 된다.
- 데이터셋 라이브러리 설치하기
!pip install roboflow
- 데이터셋 라이브러리 불러오기
from roboflow import Roboflow
- 데이터셋 설치하기
# 처리한 부분은 개인마다 다르다.
rf = Roboflow(api_key="#############")
project = rf.workspace("########").project("########")
version = project.version(1)
dataset = version.download("yolov8")
2. 모델링
- 모델링 라이브러리 설치하기
!pip install ultralytics
- 모델링 라이브러리 불러오기
from ultralytics import YOLO, settings
- 데이터셋 경로 수정 & YAML 파일 경로 수정
settings['datasets_dir'] = '/content/'
settings.update()
settings
여기서! 코랩 환경에서 사용하는 사람들은 오류가 있을 수 있기 때문에 'data.yaml' 파일을 열어서 ' ../ ' 형식으로 경로를 수정해준다.
import yaml
# yaml 파일 읽고 수정 필요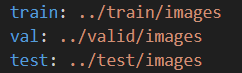
1) 모델 구조만 빌려와서 사용해보기
yolov8n.yaml 파일을 사용하고, pretrained=False로 설정하면 전이 학습을 사용하지 않고 모델을 처음부터 훈련시킨다.
즉, 모델의 가중치가 처음부터 무작위로 초기화되고, 주어진 데이터셋에 대해 전체 학습 과정을 거친다.
- 모델 구조 선택하기
model = YOLO(model='yolov8n.yaml', task='detect')
- 모델 학습하기
model.train(data='/content/Climbing-1/data.yaml',
epochs=150,
patience=7,
pretrained=False,
verbose=True,
seed=1234,
)
마지막 줄에 있는 'runs/detect/train' 경로로 가면 학습 결과를 그래프 등으로 확인할 수 있다.
- 모델 학습 결과 확인
- 예측해보기
results = model1.predict(source='/content/Climbing-1/test/images/*',
save=True,
line_width=2,
stream=True
)
for r in results :
r_bbox = r.boxes위 코드를 실행하면

이런 식으로 예측 결과 이미지가 들어있는 경로를 알려준다. 이 경로로 들어가면 결과를 확인할 수 있다.
2) 모델 구조에 사전 학습 가중치도 가져와서 사용해보기
yolov8n.pt 파일을 사용한다. '.pt '확장자는 PyTorch 모델의 가중치 파일을 의미한다.
pretrained=True로 설정되어 있어, 사전에 훈련된 가중치를 사용하고 이를 기반으로 추가 학습을 수행한다.
이 방법은 일반적으로 학습 속도를 높이고, 더 빨리 높은 성능에 도달할 수 있도록 돕는다.
- 모델 구조 및 사전학습 가중치 선택하기
model2 = YOLO(model='yolov8n.pt', task='detect')
- 모델 학습하기
model2.train(data='/content/Climbing-1/data.yaml',
epochs=150,
patience=10,
pretrained=True,
verbose=True,
seed=1234,
)
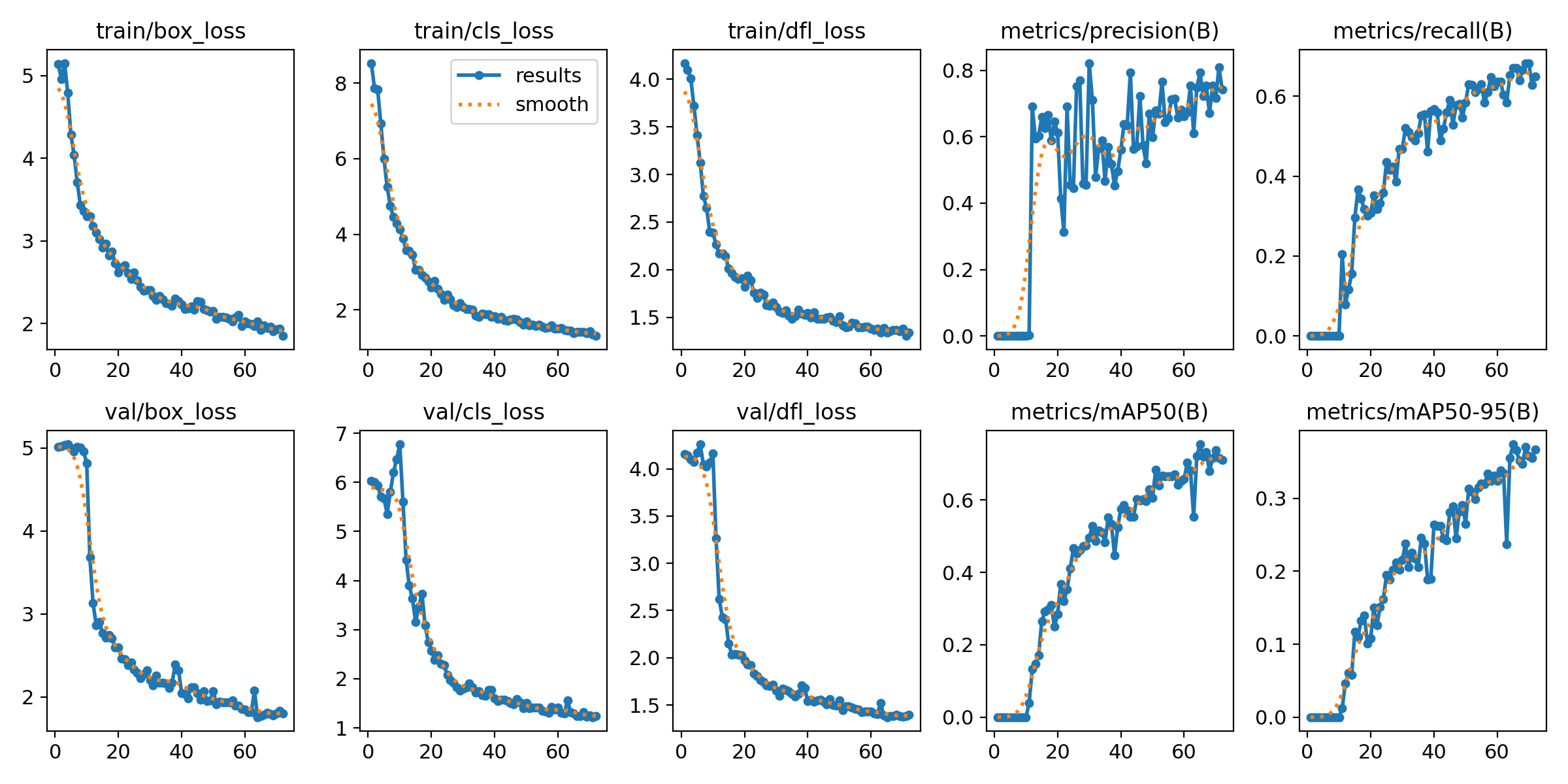
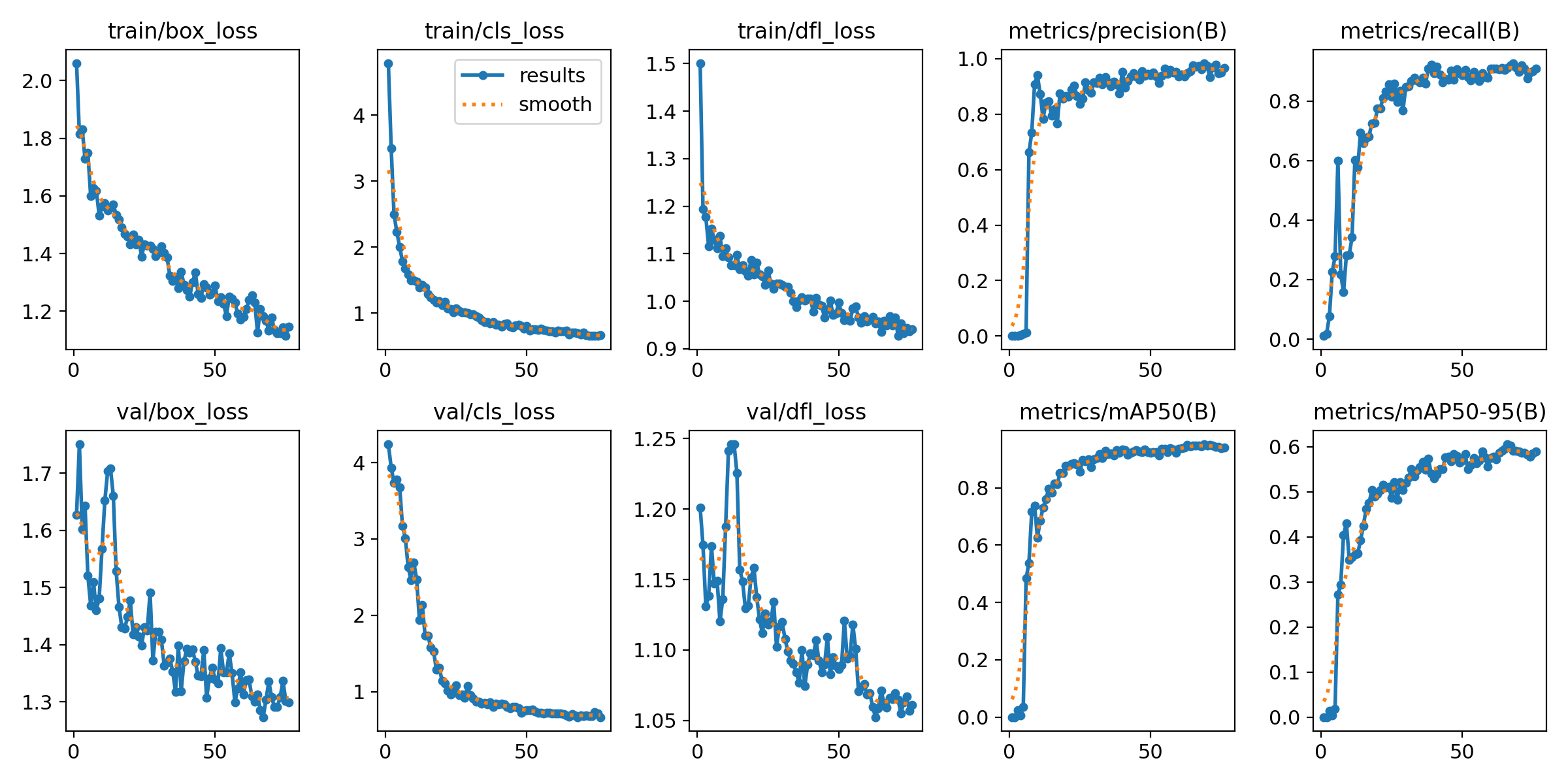
mAP50이 0.948, mAP50-95가 0.606으로 사전 학습 가중치도 가져와서 학습하는 것이 성능이 훨씬 좋다.
- 예측해보기
다른 test 이미지도 직접 넣어 확인 해 봤다.
# 이미지 한 장 test
results = model2.predict(source='/content/Climbing-1/test01.jpg',
save=True,
line_width=2,
stream=True
)
## 이미지 여러 장 test
# results = model2.predict(source='/content/Climbing-1/test/*',
# save=True,
# line_width=2,
# stream=True
# )
## 영상 test
# results = model2.predict(source='/content/Climbing-1/test02.mp4',
# save=True,
# line_width=2,
# stream=True
# )
for r in results :
r_bbox = r.boxes
3. 예측 결과
모델링 결과는 다음 사이트를 참고해서 확인했다.
https://docs.ultralytics.com/ko/reference/utils/metrics/#ultralytics.utils.metrics.Metric.mp
메트릭
혼동 행렬, 탐지 메트릭, 포즈 메트릭, 박스 IoU 등 다양한 메트릭 도구( Ultralytics YOLO )를 살펴보세요. 정밀도 리콜 곡선을 계산하고 플롯하는 방법을 알아보세요.
docs.ultralytics.com
예측 결과 비교
모델 구조만 사용 |
사전 학습 가중치도 사용 |
|
| mAP50 | 0.756 | 0.948 |
| mAP50-95 | 0.373 | 0.606 |
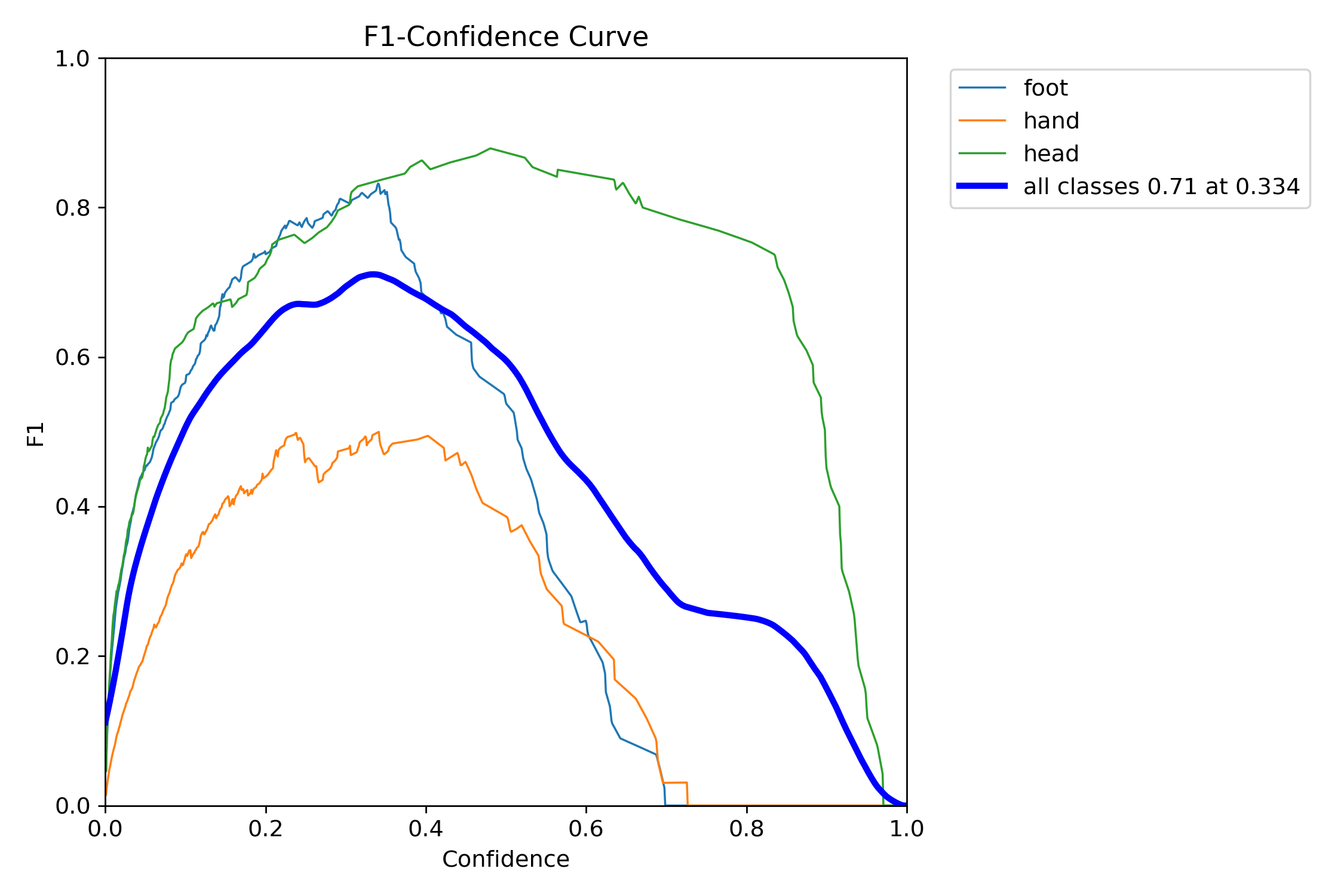
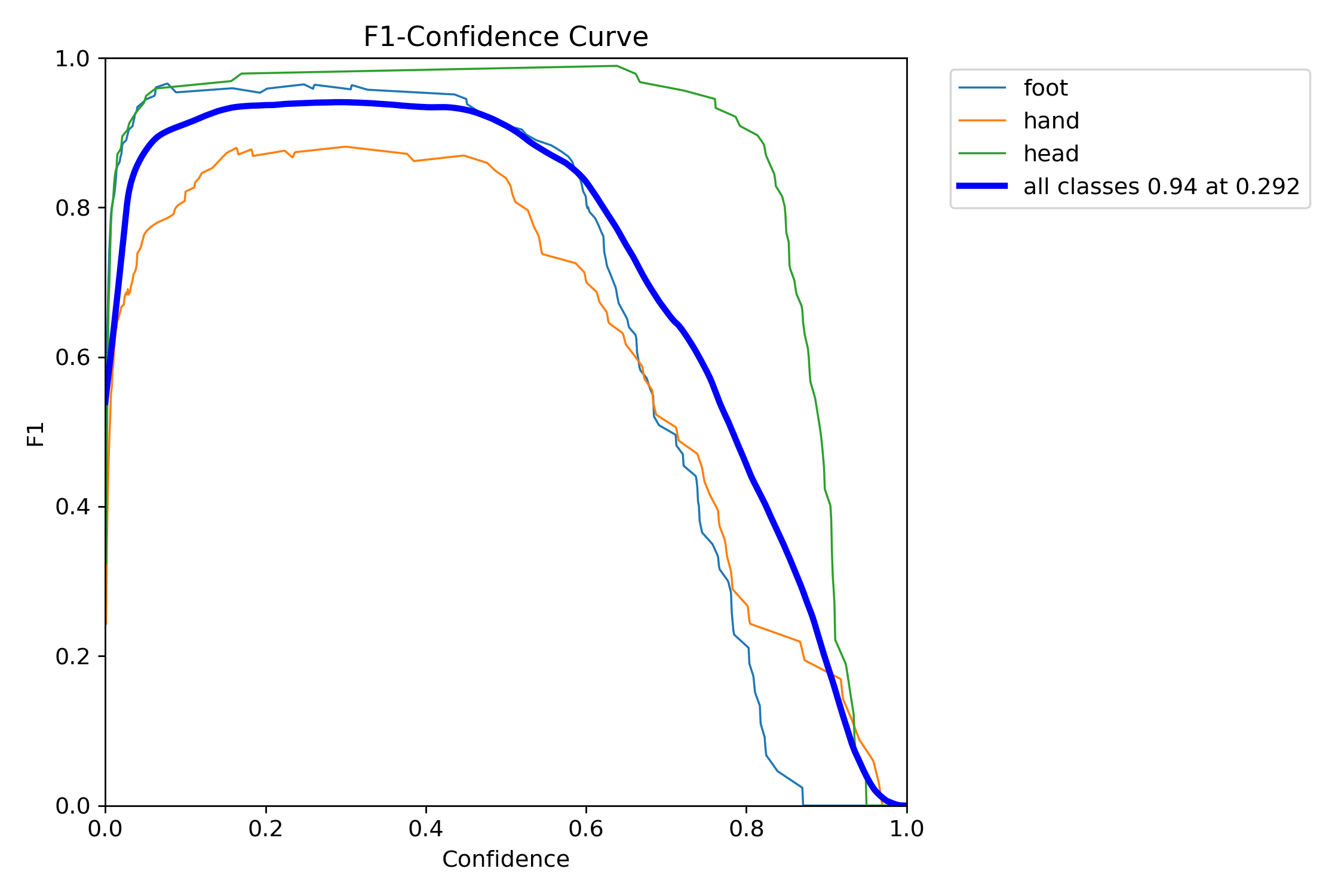




Test
train에 사용하지 않은 사진과 영상을 몇 장 테스트 해 보았다. 200장 정도의 적은 학습 데이터와 작은 모델, 학습률로 이정도 예측하는 걸 보면 모델 학습이 잘 되었다고 생각한다.




마무리
- 클라이밍 영상 데이터를 프레인단위의 이미지로 변환하였기 때문에 움직이는 순간의 이미지들은 발, 손 등이 흐리게 나타난 경우도 있었다.

이런 식으로.. 나는 최종적으로 클라이밍 영상에서 머리, 손, 발 위치를 추정하고자 했기 때문에, 이런 이미지도 라벨링을 해주면 프레임 단위로도 예측을 더 잘하고, 성능이 더 좋아질거라 생각했다. 그래서 이런 이미지도 최대한 맞춰 Bounding Box를 그려줬고, 이게 성능에 영향을 주었는지는 잘 모르겠다..
- 데이터 수집, 전처리, 라벨링까지 하는 작업이 힘들었지만, 이미 학습된 모델을 생각보다 간단히 활용할 수 있었고, 성능도 생각보다 좋아서 뿌듯했다. 또 하라고 해도 할 만한 작업이었다고 생각한다.
- 내가 계속 해보고 싶었던 클라이밍 영상에서 관절 위치를 찾는 것에서 조금 간단하게? 머리, 손, 발을 찾는 프로젝트를 해보면서 나중에 돌의 위치, 사람의 자세 등을 파악해 루트를 알려주거나 하는 서비스를 만들어도 될 것 같다.
특히 내가 가장 해보고 싶은 건, 클라이밍을 하다보면 온 힘을 다해 Top을 찍고, 내려올 힘이 많이 남지 않아 내려올 때 부상을 당하거나 하는 경우를 많이 봤다. 또한 막상 벽에 올라가면 돌이 시야에 잘 들어오지 않아서 내려오는데 애를 먹은 적이 많다. 이러한 경우를 대비해 사람의 위치에 대비해 내려올 때 잡거나 밟을 수 있는 돌의 위치를 음성으로 알려주는 서비스를 만들어보고싶다.
전체 코드는 깃허브에서 확인할 수 있다.
https://github.com/suetudy/Sues_Projects
GitHub - suetudy/Sues_Projects
Contribute to suetudy/Sues_Projects development by creating an account on GitHub.
github.com
'프로젝트' 카테고리의 다른 글
| 인공위성 데이터로 도시 환경 개선하기 - 쿨루프 시공 대상 여부 분류 (0) | 2024.04.15 |
|---|---|
| 차량 공유 업체의 차량 파손 여부 분류하기(3) - Transfer Learning (0) | 2024.04.14 |
| 차량 공유 업체의 차량 파손 여부 분류하기(2) - CNN 모델링 (0) | 2024.04.09 |
| 차량 공유 업체의 차량 파손 여부 분류하기(1) - 데이터 확인 및 전처리 (0) | 2024.04.09 |
| YOLOv8와 Roboflow를 활용한 Object Detection - 클라이밍 이미지에서 얼굴, 손, 발 detection(1) (0) | 2024.04.08 |