
프로젝트 소개 및 도메인 이해
차량 공유란?
자동차의 소유권을 가지고 있는 주체가 서비스에 가입된 회원에게 시간단위로 차량의 이용권한을 제공하는 것이다.
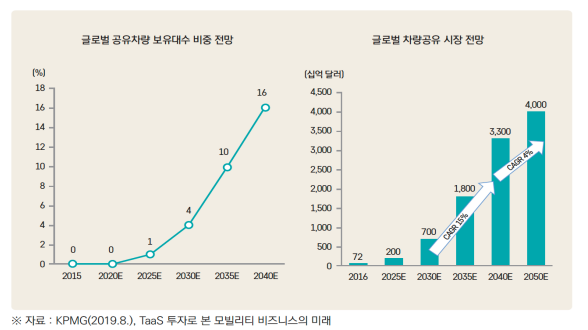
전 세계적으로 공유차량 보유대수가 가파른 성장세를 보이며, 2040년까지 16% 증가할 것으로 보인다.
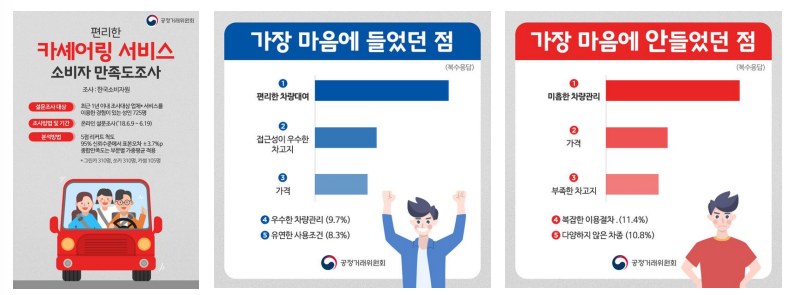
만족도 조사 결과 사용자 입장에서는 편리한 차량 대여와 차량 관리를 중요하게 생각는 것을 알 수 있다.
차량 공유 사용 절차

차량 공유 업체에서는 차량 상태 확인을 위한 외관촬영 검수를 한다. 고객이 전송한 외관 찰영 사진은 일평균 7~8만장으로, 최대 11만장의 차량 외관 이미지를 검수하기도 한다.
차량공유업체에서는 차량 사진을 일일히 수작업을 통해 파손된 차량을 식별하고 차량 정비를 맡기는 업무가 가장 많은 시간과 인력 등의 비용을 소비한다.
이러한 작업은 소비자의 만족도와 안전에 직결되므로 매우 중요하며, 필수적이다.
따라서 차량의 파손 여부를 자동으로 식별하고 알려주는 서비스를 만들면 매우 편리할 것이다.
위와 같은 도메인 지식으로 CNN 모델링 및 Transfer Learning을 통한 차량 공유 업체의 차량 파손 여부를 분류하는 프로젝트를 진행했다.
데이터
학습 데이터는 DALL-E로 만든 정상 차량 사진 302장과, 파손된 차량의 사진 303장으로 총 605장의 이미지 데이터를 사용한다.
1. 환경 설정
!pip install keras --upgrade
import os
os.environ['KERAS_BACKEND'] = 'tensorflow'
(1) 라이브러리 불러오기
import gdown, zipfile
import os, glob, shutil
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
import os
import random
from PIL import Image
from sklearn.model_selection import train_test_split
import keras
(2) 데이터 불러오기
1) 데이터 다운로드
2) 데이터 압축 해제
def dataset_extract(file_name):
with zipfile.ZipFile(file_name, 'r') as zip_ref :
file_list = zip_ref.namelist()
if os.path.exists(f'/content/{file_name[-14:-4]}/') :
print(f'데이터셋 폴더가 이미 존재합니다.')
return
else :
for f in tqdm(file_list, desc='Extracting', unit='files'):
zip_ref.extract(member=f, path=f'/content/{file_name[-14:-4]}/')from google.colab import drive
drive.mount('/content/drive')dataset_extract('/content/drive/MyDrive/Colab Notebooks/KT_MP_4_1/Car_Images.zip')
3) 데이터 조회
# 폴더별 이미지 데이터 갯수 확인
# 데이터셋 디렉토리 경로 설정
dataset_directory = '/content/Car_Images/'
# 서브디렉토리 리스트 얻기
subdirectories = [d for d in os.listdir(dataset_directory) if os.path.isdir(os.path.join(dataset_directory, d))]
# 각 서브디렉토리 내의 파일 개수 계산 및 출력
for subdir in tqdm(subdirectories, desc='Counting files in subdirectories'):
# 서브디렉토리의 전체 경로
subdir_path = os.path.join(dataset_directory, subdir)
# 서브디렉토리 내의 파일 리스트 얻기
files = [f for f in os.listdir(subdir_path) if os.path.isfile(os.path.join(subdir_path, f))]
# 파일 개수 출력
print(f'{subdir}: {len(files)} files')normal: 302 files
abnormal: 303 files
# 정상 차량 랜덤 이미지 확인 및 형태 확인
path_normal = '/content/Car_Images/normal'
# 해당 경로의 파일 목록 가져오기
files = os.listdir(path_normal)
# 랜덤 파일 선택
random_file = random.choice(files)
# 이미지 경로
img_path = os.path.join(path_normal, random_file)
# 이미지 열기
img = Image.open(img_path)
# 이미지 보여주기
plt.imshow(img)
plt.axis('off') # 축 끄기
plt.show()
# 이미지 크기 출력
print(f'Random image size: {img.size}')
# 파손 차량 랜덤 이미지 확인 및 형태 확인
path_abnormal = '/content/Car_Images/abnormal'
# 해당 경로의 파일 목록 가져오기
files = os.listdir(path_abnormal)
# 랜덤 파일 선택
random_file = random.choice(files)
# 이미지 경로
img_path = os.path.join(path_abnormal, random_file)
# 이미지 열기
img = Image.open(img_path)
# 이미지 보여주기
plt.imshow(img)
plt.axis('off') # 축 끄기
plt.show()
# 이미지 크기 출력
print(f'Random image size: {img.size}')
2. 데이터 전처리
모델링을 위한 데이터 구조 만들기
(1) Y: 클래스 만들기
전체 데이터에 대한 Y를 생성한다.
normal: 0
abnormal: 1
# normal 이미지의 수 확인
num_normal = len([name for name in os.listdir(path_normal) if os.path.isfile(os.path.join(path_normal, name))])
# abnormal 이미지의 수 확인
num_abnormal = len([name for name in os.listdir(path_abnormal) if os.path.isfile(os.path.join(path_abnormal, name))])
# Y 배열 생성: normal은 0, abnormal은 1
Y = np.array([0]*num_normal + [1]*num_abnormal)
print(Y.shape)(605,)
(2) X: 데이터 리스트 통합
처음과 마지막 2개씩 확인해 본 결과 normal 뒤에 abnormal이 잘 들어간걸 확인할 수 있다.
X = glob.glob("/content/Car_Images/normal/*") + glob.glob("/content/Car_Images/abnormal/*")
print(X[:3])
print(X[-3:])['/content/Car_Images/normal/DALLíñE 2023-03-10 23.58.53 - a part of car without blemish.png', '/content/Car_Images/normal/DALLíñE 2023-03-11 14.12.31 - part of a car.png'] ['/content/Car_Images/abnormal/DALLíñE 2023-03-11 18.45.06 - slightly dented car.png', '/content/Car_Images/abnormal/DALLíñE 2023-03-11 17.16.24 - damaged car.png']
(3) 데이터셋 분리
1) train set, test set = 90%, 10%
2) train set, valid set = 90% 10%
# 1) train set, test set = 90%, 10%
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.1, random_state=42)
# 2) train set, valid set = 90%, 10%
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, random_state=42)
# 결과 출력
print(f'훈련 데이터셋 크기: {len(x_train)}, {y_train.shape}')
print(f'검증 데이터셋 크기: {len(x_valid)}, {y_valid.shape}')
print(f'테스트 데이터셋 크기: {len(x_test)}, {y_test.shape}')훈련 데이터셋 크기: 489, (489,)
검증 데이터셋 크기: 55, (55,)
테스트 데이터셋 크기: 61, (61,)
(4) X: image to array
1) 이미지 np.array 형태로 변환
2) 이미지 사이즈 줄이기
3) 스케일링
def x_preprocessing(img_list) :
bin_list = []
for img in tqdm(img_list) :
img = keras.utils.load_img(img, target_size=(128, 128)) # image resize
img = keras.utils.img_to_array(img)
img /= 255.0 # scaling
bin_list.append(img)
return np.array(bin_list)x_train = x_preprocessing(x_train)
x_valid = x_preprocessing(x_valid)
x_test = x_preprocessing(x_test)# 변환 후의 크기 확인
print(f'훈련 데이터셋 크기: {x_train.shape}')
print(f'검증 데이터셋 크기: {x_valid.shape}')
print(f'테스트 데이터셋 크기: {x_test.shape}')훈련 데이터셋 크기: (489, 128, 128, 3)
검증 데이터셋 크기: (55, 128, 128, 3)
테스트 데이터셋 크기: (61, 128, 128, 3)
'프로젝트' 카테고리의 다른 글
| 인공위성 데이터로 도시 환경 개선하기 - 쿨루프 시공 대상 여부 분류 (0) | 2024.04.15 |
|---|---|
| 차량 공유 업체의 차량 파손 여부 분류하기(3) - Transfer Learning (0) | 2024.04.14 |
| 차량 공유 업체의 차량 파손 여부 분류하기(2) - CNN 모델링 (0) | 2024.04.09 |
| YOLOv8와 Roboflow를 활용한 Object Detection - 클라이밍 이미지에서 얼굴, 손, 발 detection(2) (0) | 2024.04.08 |
| YOLOv8와 Roboflow를 활용한 Object Detection - 클라이밍 이미지에서 얼굴, 손, 발 detection(1) (0) | 2024.04.08 |