
CNN 모델링
4가지 모델 구조를 만들고 성능을 비교 해 본다.
환경 설정
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout, Input, MaxPool2D
from keras.backend import clear_session
from keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report, confusion_matrix
학습 곡선 함수
# 학습곡선 함수
def dl_history_plot(history):
plt.figure(figsize=(10,6))
plt.plot(history['loss'], label='train_err', marker = '.')
plt.plot(history['val_loss'], label='val_err', marker = '.')
plt.ylim([0, 3])
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.grid()
plt.show()
모델의 예측 결과 랜덤으로 하나 씩 확인해 보는 함수
import numpy as np
import matplotlib.pyplot as plt
import random as rd
# labels 딕셔너리
labels = {0: 'normal', 1: 'abnormal'}
# 모델의 예측 결과 확인 해 보기
def check_pred(model, labels, x_test, y_test):
predictions = model.predict(x_test)
id = rd.randrange(0, len(x_test))
print(f'id = {id}')
print(f'다음 그림은 {labels[y_test[id]]} 입니다.')
prob_abnormal = np.floor(predictions[id][0]*100).tolist()
prob_normal = np.floor((1 - predictions[id][0])*100).tolist()
prob_dict = {
labels[0]: prob_normal,
labels[1]: prob_abnormal
}
print('모델의 카테고리별 확률 : ')
print(prob_dict)
print()
# 정답 여부 확인
single_pred_test = (predictions > 0.5).astype(int).flatten()
if y_test[id] == single_pred_test[id]:
print('정답입니다')
else:
print('틀렸어요')
plt.imshow(x_test[id])
plt.show()
모델 input_shape
# input_shape : feature 수 도출
nfeatures = x_train.shape[1:]
nfeatures(128, 128, 3)
1. Model1
1) 구조 설계
# 메모리 정리
clear_session()
# 모델 구조 설계
model1 = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=nfeatures),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid')
])
# 모델 컴파일
model1.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 요약
model1.summary()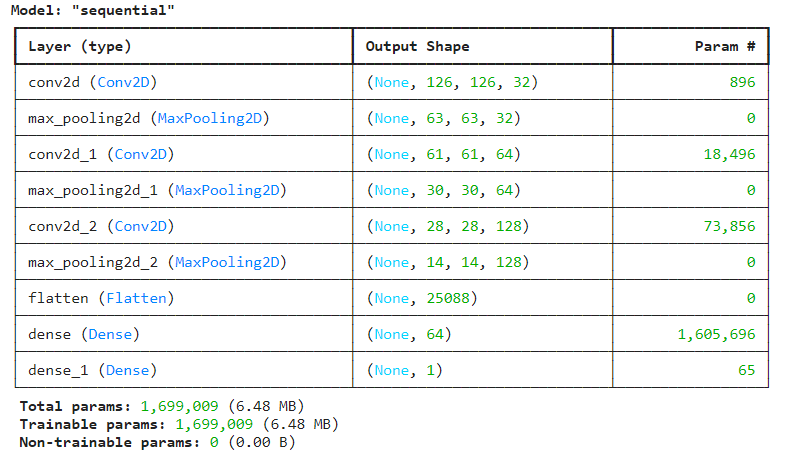
2) 학습
# EarlyStopping 설정
min_de = 0
pat = 10
es = EarlyStopping(monitor = 'val_loss', min_delta = min_de, patience = pat)
# 학습
hist = model1.fit(x_train, y_train, epochs = 100, validation_data=(x_valid, y_valid),
callbacks = [es]).history
dl_history_plot(hist)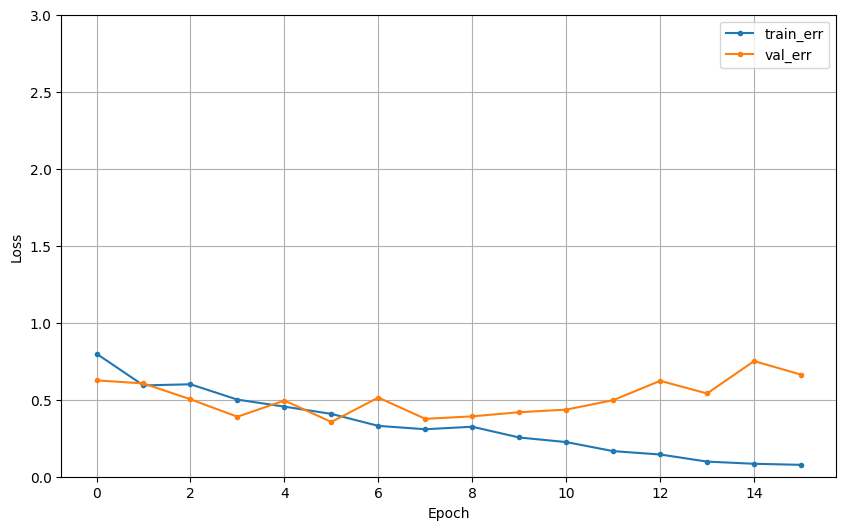
3) 성능 평가
# 테스트 데이터셋에 대한 예측 수행
predictions = model1.predict(x_test)
predictions = np.round(predictions).astype(int) # 확률을 이진 값으로 변환
print('Model1')
# Confusion Matrix 출력
print("Confusion Matrix:")
print(confusion_matrix(y_test, predictions))
# Classification Report 출력
print("\nClassification Report:")
print(classification_report(y_test, predictions))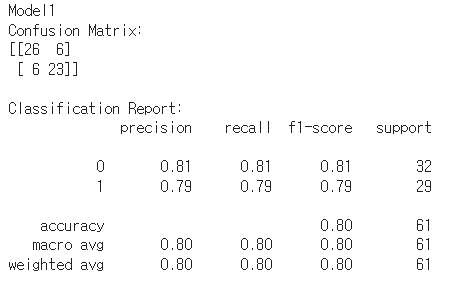
check_pred(model1, labels, x_test, y_test)


Model1
- accuracy가 가장 높음
2. Model2
1) 구조 설계
# 메모리 정리
clear_session()
# 모델 구조 설계
model2 = Sequential([
Conv2D(32, (3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=nfeatures),
Conv2D(32, (3, 3), strides=(1, 1), padding='same', activation='relu'),
BatchNormalization(),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Dropout(0.25),
Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu'),
Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu'),
BatchNormalization(),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Dropout(0.25),
Flatten(),
Dense(1024, activation='relu'),
BatchNormalization(),
Dropout(0.35),
Dense(1, activation='sigmoid')
])
# 모델 컴파일
model2.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 요약
model2.summary()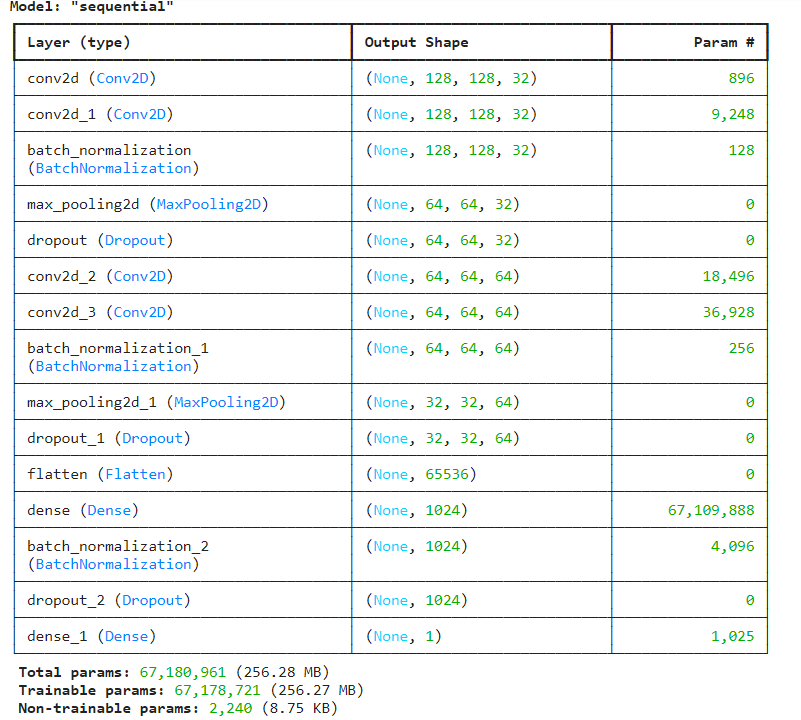
2) 학습
# EarlyStopping 설정
min_de = 0
pat = 10
es = EarlyStopping(monitor = 'val_loss', min_delta = min_de, patience = pat)
# 학습
hist = model2.fit(x_train, y_train, epochs = 100, validation_data=(x_valid, y_valid),
callbacks = [es]).history
dl_history_plot(hist)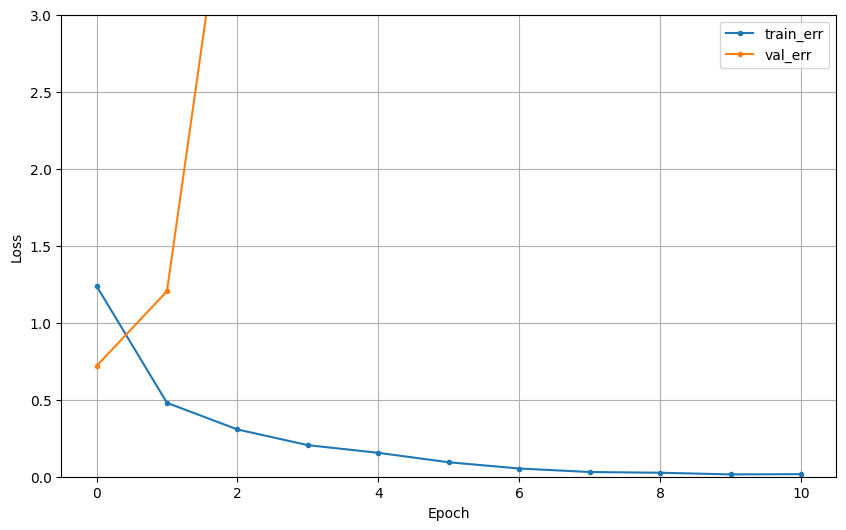
3) 성능 평가
# 테스트 데이터셋에 대한 예측 수행
predictions = model2.predict(x_test)
predictions = np.round(predictions).astype(int) # 확률을 이진 값으로 변환
print('Model2')
# Confusion Matrix 출력
print("Confusion Matrix:")
print(confusion_matrix(y_test, predictions))
# Classification Report 출력
print("\nClassification Report:")
print(classification_report(y_test, predictions))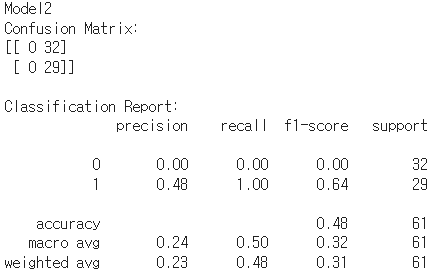
check_pred(model2, labels, x_test, y_test)


Model2
- 그래프 확인 결과 오버피팅 된 것을 확인할 수 있음
- 모델 구조가 너무 깊다
- 테스트 예측 결과도 좋지 않음
3. Model3
1) 구조 설계
# 메모리 정리
clear_session()
# 모델 구조 설계
model3 = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=nfeatures),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25),
Flatten(),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')])
# 모델 컴파일
model3.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 요약 출력
model3.summary()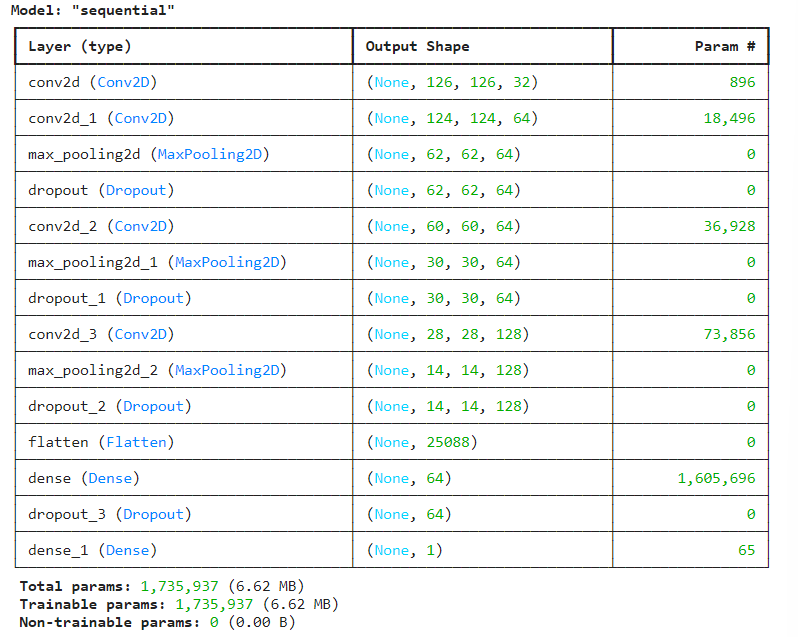
2) 학습
# EarlyStopping 설정
min_de = 0
pat = 10
es = EarlyStopping(monitor = 'val_loss', min_delta = min_de, patience = pat)
# 학습
hist = model3.fit(x_train, y_train, epochs = 100, validation_data=(x_valid, y_valid),
callbacks = [es]).history
dl_history_plot(hist)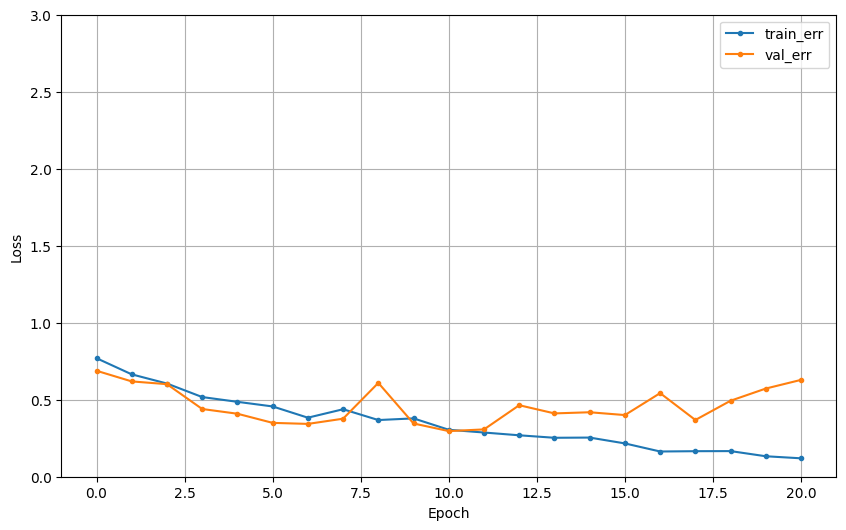
3) 성능 평가
# 테스트 데이터셋에 대한 예측 수행
predictions = model3.predict(x_test)
predictions = np.round(predictions).astype(int) # 확률을 이진 값으로 변환
print('Model3')
# Confusion Matrix 출력
print("Confusion Matrix:")
print(confusion_matrix(y_test, predictions))
# Classification Report 출력
print("\nClassification Report:")
print(classification_report(y_test, predictions))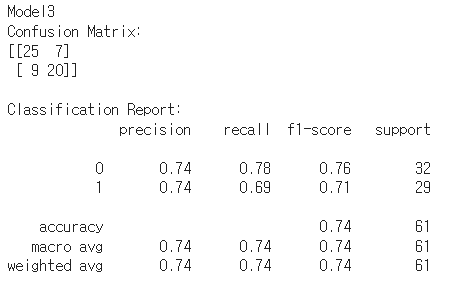
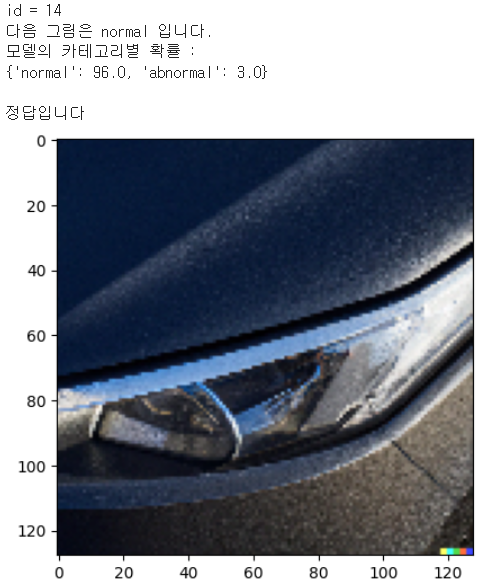


Model3
- accurracy가 두 번째로 높다
- 테스트 데이터 확인해 본 결과 성능 나쁘지 않음
- abnormal에서 너무 작은 스크레치 등은 잘 구분하지 못
4. Model4
1) 구조 설계
# 메모리 정리
clear_session()
# 모델 구조 설계
model4 = Sequential([
Conv2D(256, kernel_size=(5, 5), activation='relu', padding='same', input_shape=input_shape),
Conv2D(256, (5, 5), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(128, (3, 3), activation='relu', padding='same'),
Conv2D(128, (3, 3), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
# 모델 컴파일
model4.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 요약 출력
model4.summary()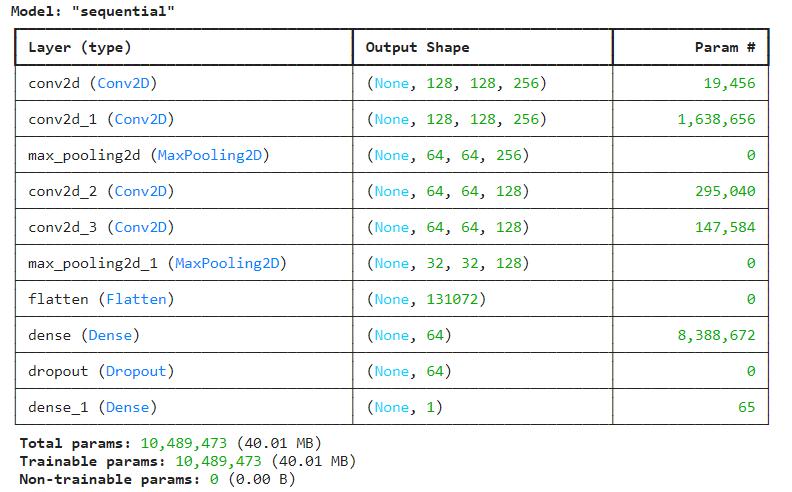
2) 학습
# EarlyStopping 설정
min_de = 0
pat = 10
es = EarlyStopping(monitor = 'val_loss', min_delta = min_de, patience = pat)
# 학습
hist = model4.fit(x_train, y_train, epochs = 100, validation_data=(x_valid, y_valid),
callbacks = [es]).history
dl_history_plot(hist)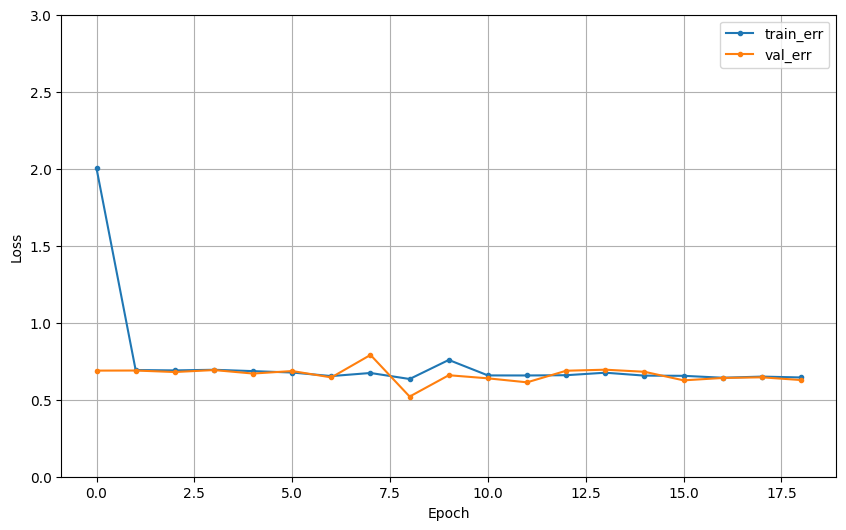
3) 성능 평가
# 테스트 데이터셋에 대한 예측 수행
predictions = model3.predict(x_test)
predictions = np.round(predictions).astype(int) # 확률을 이진 값으로 변환
print('Model4')
# Confusion Matrix 출력
print("Confusion Matrix:")
print(confusion_matrix(y_test, predictions))
# Classification Report 출력
print("\nClassification Report:")
print(classification_report(y_test, predictions))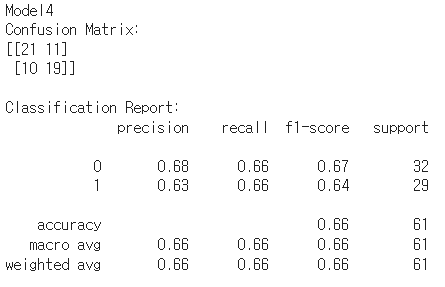
check_pred(model4, labels, x_test, y_test)

Model4
- 소심한 모델인 것 같음
- 각 카테고리 일 확률이 어느 한쪽으로 크게 치우치지 않음
'프로젝트' 카테고리의 다른 글
| 인공위성 데이터로 도시 환경 개선하기 - 쿨루프 시공 대상 여부 분류 (0) | 2024.04.15 |
|---|---|
| 차량 공유 업체의 차량 파손 여부 분류하기(3) - Transfer Learning (0) | 2024.04.14 |
| 차량 공유 업체의 차량 파손 여부 분류하기(1) - 데이터 확인 및 전처리 (0) | 2024.04.09 |
| YOLOv8와 Roboflow를 활용한 Object Detection - 클라이밍 이미지에서 얼굴, 손, 발 detection(2) (0) | 2024.04.08 |
| YOLOv8와 Roboflow를 활용한 Object Detection - 클라이밍 이미지에서 얼굴, 손, 발 detection(1) (0) | 2024.04.08 |