
빅데이터분석기사 실기 기출문제를 풀던 중 train 데이터와 test 데이터의 범주형 변수의 범주가 서로 다른 경우가 있었다.
예를 들면 이런 식이다.
train['지역'] = ['서울', '인천', '경기']
test['지역'] = ['서울', '인천', '부산']
위와 같은 경우에 get_dummies를 이용해 가변수화 하면 서로 다른 컬럼이 만들어지기 때문에 train 데이터로 학습해서 test 데이터를 예측하면 오류가 발생한다.
해결 방법
train 데이터와 test 데이터를 합쳐서 전처리를 하고, 다시 나눠준다.
# train, test 합치기
X_all = pd.concat([train, test], keys=['train', 'test'])
# 가변수화
X_all = pd.get_dummies(X_all)
# train, test 다시 분리
trian = X_all.xs('train')
test = X_all.xs('test')concat 할 때 keys는 아무거나 알아볼 수 있는 이름으로 하면 되고, 나중에 분리할 때 키로 사용된다.
꿀팁!
EDA를 할 때 다음과 같은 코드로 unique 값이 train과 test가 동일한지 확인한다! 확인 결과 동일하지 않으면 범주가 서로 다르기 때문에 위와 같은 전처리 과정을 거쳐 주어야 한다.
train.describe(include='object')
test.describe(include='object')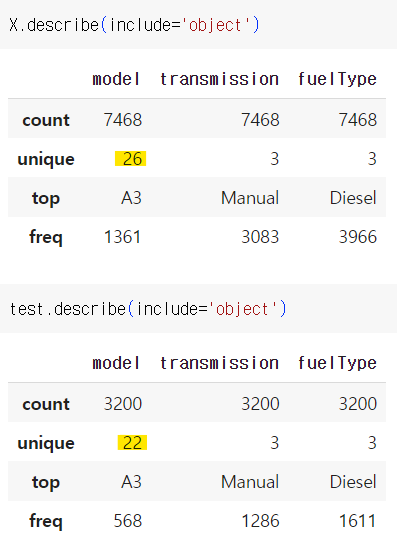
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 실기] 총 정리 - 깃허브 (0) | 2024.05.28 |
|---|---|
| [빅데이터분석기사 실기] 제3유형: 통계적 가설검정(2) (0) | 2024.05.28 |
| [빅데이터분석기사 실기] 제3유형: 통계적 가설검정(1) (0) | 2024.05.25 |
| [빅데이터분석기사 실기] 제2유형: 데이터 분석 (0) | 2024.05.22 |
| [빅데이터분석기사 실기] 제1유형: 데이터 전처리 (0) | 2024.05.18 |
빅데이터분석기사 실기 기출문제를 풀던 중 train 데이터와 test 데이터의 범주형 변수의 범주가 서로 다른 경우가 있었다.
예를 들면 이런 식이다.
train['지역'] = ['서울', '인천', '경기']
test['지역'] = ['서울', '인천', '부산']
위와 같은 경우에 get_dummies를 이용해 가변수화 하면 서로 다른 컬럼이 만들어지기 때문에 train 데이터로 학습해서 test 데이터를 예측하면 오류가 발생한다.
해결 방법
train 데이터와 test 데이터를 합쳐서 전처리를 하고, 다시 나눠준다.
# train, test 합치기
X_all = pd.concat([train, test], keys=['train', 'test'])
# 가변수화
X_all = pd.get_dummies(X_all)
# train, test 다시 분리
trian = X_all.xs('train')
test = X_all.xs('test')concat 할 때 keys는 아무거나 알아볼 수 있는 이름으로 하면 되고, 나중에 분리할 때 키로 사용된다.
꿀팁!
EDA를 할 때 다음과 같은 코드로 unique 값이 train과 test가 동일한지 확인한다! 확인 결과 동일하지 않으면 범주가 서로 다르기 때문에 위와 같은 전처리 과정을 거쳐 주어야 한다.
train.describe(include='object')
test.describe(include='object')'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 실기] 총 정리 - 깃허브 (0) | 2024.05.28 |
|---|---|
| [빅데이터분석기사 실기] 제3유형: 통계적 가설검정(2) (0) | 2024.05.28 |
| [빅데이터분석기사 실기] 제3유형: 통계적 가설검정(1) (0) | 2024.05.25 |
| [빅데이터분석기사 실기] 제2유형: 데이터 분석 (0) | 2024.05.22 |
| [빅데이터분석기사 실기] 제1유형: 데이터 전처리 (0) | 2024.05.18 |